Как удалить все после определенного символа
29 Nov 2024 | Автор: dd |По мотивам всяких разных парсингов выдачи очень часто бывает необходимо избавиться от хвостов в урле, чтобы остался только домен. Делается это путем небольших манипуляций в Notepad++
И есть http:// убирается просто через обычную замену данных символов на пустое поле, в форме замены (вызываем поиск через Ctrl+F и далее вкладка “замена”), то подобная операция осуществляется через регулярные выражения, которые выставляются в поле “Режим поиска”
Предположим что у нас есть набор улов:
сайт1/урл1
сайт1/урл2
сайт2/урл101
сайт2/урл100500
сайт3/урл1001
и надо убрать все от слеша после домена.
Для это используем выражение поиска (/.+)$ которое охватывает весь адрес от первого слеша. Перед этим естественно желательно убрать первоначальные http:// и https:// ибо иначе выражение будет работать от первого слеша.
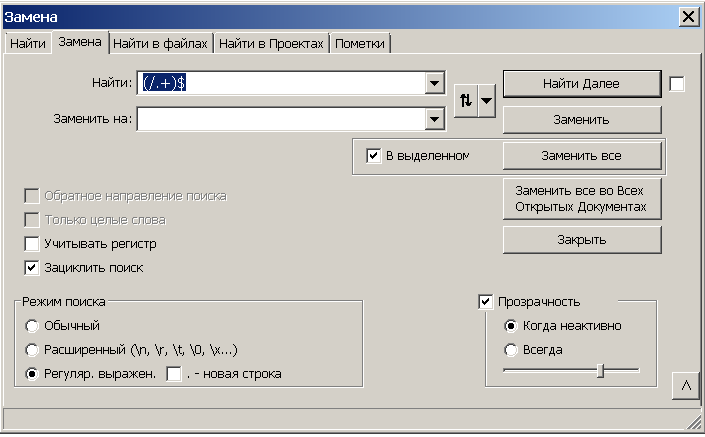
После чего производим замену выражения на пустую строку.
Если же надо было бы удалить все до слеша включительно, то выражение бы выглядело как .+(/), только слеш в данном случае был бы последний, т.ч там где урл бы оканчивался на слеш, вообще бы ничего не осталось.
Как удалить все после определенного символа,